

Three months back, a mid-sized healthcare training company brought me in after their certification program nearly lost accreditation. Not because their assessments were bad—they had solid content. The problem? Their lead psychometrician discovered that 47% of their exam items had been modified without review, their SMEs were approving items outside their expertise areas, and nobody could explain why pass rates dropped 23% over six months.
The kicker: they had 14 people involved in assessment development, but zero clarity on who was responsible for what.
This breakdown happens constantly when assessment programs grow past about 500 test-takers monthly. The informal "we'll figure it out" approach that works fine for smaller programs completely collapses once you need multiple item writers, reviewers, and quality checks running simultaneously.
The hidden complexity explosion in assessment operations
Most assessment programs start simple. One instructor writes questions, maybe gets a colleague to review them, uploads to the LMS, done. Works great for 30-person cohorts.
But watch what happens as programs scale:
At 200 monthly test-takers, you need backup item writers because your main person gets overwhelmed. Now you have consistency issues—one writer creates scenario-based questions while another prefers straight recall. Nobody notices until learners complain about uneven difficulty.
At 500 monthly test-takers, you add subject matter experts for review. Except they start rewriting items instead of just checking accuracy. Your carefully calibrated difficulty levels get scrambled. Pass rates swing wildly between test forms.
At 1,000+ monthly test-takers, regulatory requirements kick in. You need documented review processes, statistical validation, fairness checks. Suddenly you're drowning in spreadsheets tracking item performance, reviewer comments, revision histories.
The operational load doesn't grow linearly—it explodes. A program that needs 20 hours weekly at 200 test-takers needs 180+ hours at 2,000 test-takers. Not because you're writing 10x more items, but because coordination, quality control, and compliance overhead multiply exponentially.
Why traditional role definitions fail assessment programs
Standard organizational charts don't work for assessment operations. I've watched dozens of programs try to force assessment workflows into typical corporate structures. They create titles like "Assessment Coordinator" or "Testing Manager" without defining the actual operational boundaries.
Eliminate assessment bottlenecks.
Evaloly simplifies every step from test design to results analysis, making assessments faster and more reliable.
- Customizable test creation
- Automated grading and analytics
- Secure distribution and proctoring
No credit card required
The expertise mismatch hits first. Your best chemistry professor might write excellent items but has zero understanding of psychometric principles. Your instructional designer knows learning theory but can't interpret item discrimination statistics. Your data analyst can run statistical analyses but doesn't understand educational measurement standards.
Then the approval bottleneck. Programs often require director-level sign-off on every assessment change. Directors end up rubber-stamping hundreds of items monthly without meaningful review. Quality drops while everyone maintains the illusion of oversight.
Most damaging is the accountability void. When items perform poorly, nobody knows who should fix them. The item writer says they followed the template. The reviewer says they only checked content accuracy. The psychometrician says they just report statistics. Meanwhile, bad items keep appearing on live exams.
Traditional hierarchy also creates weird power dynamics. Junior item writers hesitate to flag problems in senior faculty's questions. SMEs feel their expertise trumps psychometric guidelines. IT treats assessment platforms as just another LMS when they need specialized configuration.
Building an assessment governance model that actually scales
Successful programs separate roles into three distinct tracks: content creation, quality assurance, and technical operations. Each track has clear ownership boundaries and interaction protocols.
Core Role Definitions
Item Writers own initial content creation. They're responsible for:
-
Drafting items aligned to specific learning objectives
-
Following style guides and templates exactly
-
Submitting items with required metadata (difficulty estimates, objective mapping, cognitive level)
-
Responding to reviewer feedback within 48 hours
-
Maintaining a minimum 80% approval rate on first submission
Item writers never directly edit live assessments. Everything flows through review gates.
Content Reviewers validate educational accuracy and clarity. They check:
-
Factual correctness against current standards
-
Alignment with stated objectives
-
Clarity and absence of ambiguity
-
Appropriate difficulty for target audience
-
Absence of bias or unfair advantages
Reviewers can reject items or request specific revisions but cannot rewrite items themselves. This prevents scope creep where reviews turn into complete rewrites.
Psychometricians handle statistical validation and test construction. They:
-
Analyze item performance statistics
-
Flag items for revision or retirement
-
Construct parallel test forms
-
Monitor test reliability and validity
-
Recommend cut scores based on data
The psychometrician role often gets split in smaller programs—someone handles basic statistics while consulting with an external expert quarterly.
Assessment Operations Manager coordinates the entire workflow. They:
-
Manage item development schedules
-
Track SLA compliance
-
Resolve conflicts between roles
-
Maintain item banks and versioning
-
Coordinate with IT and compliance
This role prevents the common failure where everyone assumes someone else is handling coordination.
Approval Gates That Prevent Quality Collapse
Instead of hierarchical approvals, implement sequential gates based on expertise:
Gate 1: Technical Review (24-hour SLA)
-
Grammar and formatting check
-
Metadata completeness
-
Style guide compliance
Gate 2: Content Review (48-hour SLA)
-
Subject matter accuracy
-
Objective alignment
-
Cognitive level verification
Gate 3: Psychometric Review (72-hour SLA)
-
Statistical flag checks
-
Difficulty distribution
-
Discrimination potential
Gate 4: Fairness Review (48-hour SLA)
-
Bias screening
-
Accessibility compliance
-
Language complexity analysis
Items failing any gate return to the writer with specific feedback. No item reaches production without passing all gates.
Lifecycle Stages With Clear Transitions
Every item exists in exactly one stage:
-
Draft
Initial creation, not reviewed
-
In Review
Submitted for gate reviews
-
Approved
Passed all gates, awaiting deployment
-
Active
Currently in use on live assessments
-
Under Analysis
Gathering performance data
-
Flagged
Statistical or feedback issues identified
-
In Revision
Being modified based on flags
-
Retired
No longer used, archived with reason
Stage transitions trigger automatic notifications. Writers get alerts when items are flagged. Reviewers see queue updates. This removes the constant "what's the status?" emails that bog down operations.
A simple visual helps teams map roles, gates, and stage transitions.
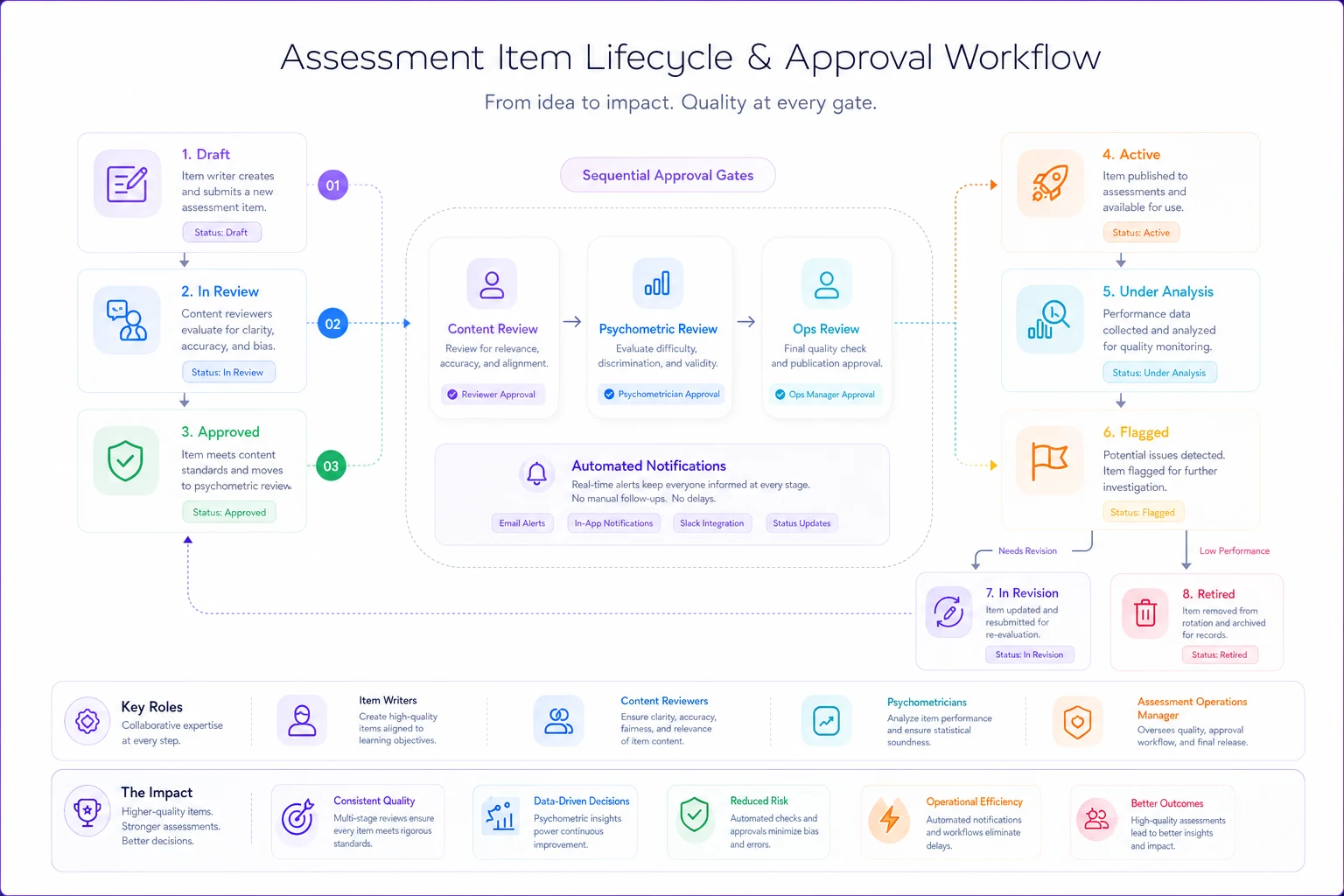
A quick visual of the workflow makes it easier to align stakeholders during rollout.
The SLA framework that keeps assessments moving
Service level agreements prevent bottleneck buildup. Without SLAs, urgent items sit for weeks while reviewers handle whoever asks loudest.
Response Time SLAs
| Response Time SLA | Target |
|---|---|
| New Item Review | 72 hours from submission to first review |
| Revision Review | 48 hours for previously reviewed items |
| Statistical Analysis | 7 days after minimum sample size reached |
| Flagged Item Resolution | 5 business days to revise or retire |
| Emergency Updates | 4 hours for critical content errors |
Quality SLAs
-
First-Pass Approval Rate
Writers maintain 75% minimum
-
Review Accuracy
Reviewers catch 90% of seeded errors in audits
-
Statistical Reliability
Test forms maintain 0.80+ reliability
-
Item Performance
No more than 15% of items flagged per cycle
Volume SLAs
-
Item Production
20 new items per writer per week
-
Review Capacity
50 items per reviewer per week
-
Analysis Throughput
200 items per psychometrician per week
Programs adjust these based on complexity. Medical certification assessments might halve these numbers. Simple knowledge checks might double them.
Ready-to-deploy checklists for assessment operations
Item Writer Submission Checklist
-
□ Learning objective explicitly identified
-
□ Correct answer verified against source material
-
□ Distractors plausible but clearly incorrect
-
□ Stem asks clear, single question
-
□ No absolute terms (always, never) unless justified
-
□ No negative phrasing unless testing exception knowledge
-
□ Difficulty estimate provided (easy/medium/hard)
-
□ Cognitive level specified (remember/understand/apply/analyze)
-
□ No grammatical clues to correct answer
-
□ Similar length for all options
-
□ No "all of the above" or "none of the above"
-
□ Referenced material less than 2 years old
Reviewer Evaluation Checklist
-
□ Content matches current standards/practices
-
□ Objective alignment verified
-
□ No ambiguous phrasing
-
□ Single best answer exists
-
□ Distractors represent common misconceptions
-
□ Appropriate for target audience level
-
□ No cultural or demographic bias
-
□ Technical terms used correctly
-
□ Scenarios realistic and relevant
-
□ No teaching in the question
-
□ Feedback explains why answer is correct
Psychometrician Analysis Checklist
-
□ Difficulty index between 0.30 and 0.85
-
□ Discrimination index above 0.20
-
□ Point-biserial correlation positive
-
□ No distractor chosen more than correct answer
-
□ All distractors chosen by at least 5% of test-takers
-
□ No obvious patterns in high/low performer responses
-
□ Item-total correlation above 0.15
-
□ No DIF flags across demographic groups
-
□ Response time within expected range
-
□ No unusual response patterns suggesting guessing
Operations Manager Audit Checklist
-
□ All SLA targets met or exceptions documented
-
□ Item bank inventory sufficient for next 90 days
-
□ Reviewer queues below maximum threshold
-
□ No items stuck in single stage >2 weeks
-
□ Writer approval rates above minimum
-
□ Test form reliability maintained
-
□ Flagged items addressed within timeline
-
□ Version control system current
-
□ Backup procedures tested
-
□ Compliance documentation updated
These checklists provide concrete acceptance criteria for each role and simplify review conversations.
When governance structure needs adjustment
Your assessment governance model isn't static. Certain triggers indicate when restructuring becomes necessary.
Volume triggers matter most. When monthly test-takers double, your review capacity needs adjustment. When item banks exceed 2,000 active items, you need dedicated bank management. When you're developing assessments for multiple programs simultaneously, role separation becomes critical.
Quality triggers are equally important. If pass rates vary more than 10% between test forms, your psychometric review needs strengthening. When item rejection rates exceed 40%, writer training or templates need revision. If post-assessment challenges increase, your review process has gaps.
Operational triggers signal system breakdown. When coordination emails exceed 3 hours daily, you need better workflow systems. If the same issues keep recurring despite fixes, your accountability structure is broken. When key people leaving causes multi-week delays, you're over-centralized.
A nursing education program I worked with ignored these triggers until their accreditation review. They'd grown from 400 to 1,400 annual test-takers without adjusting their governance model. Their lead faculty was spending 60% of her time on assessment coordination instead of teaching, they had 890 items with no performance data, and their test reliability had dropped to 0.71.
The fix took four months but wasn't complicated—clearly separated roles, implemented approval gates, established SLAs. Their test reliability climbed back to 0.84, faculty time on assessment dropped to reasonable levels, and they passed accreditation review without conditions.
Technology's role in assessment governance
Manual coordination breaks around 300 monthly test-takers. Email chains become unmanageable. Spreadsheet version control turns nightmarish. Review cycles stretch from days to weeks.
Modern assessment platforms with AI-powered workflow automation handle the coordination burden. They automatically route items through approval gates, track SLA compliance, flag statistical anomalies, and maintain audit trails. AI automation can pre-screen items for common issues before human review, flag potential bias patterns reviewers might miss, and predict which items will likely need revision based on historical patterns.
Pro-tip: Use platform audit trails to identify recurring reviewer oversights and target training.
These platforms also solve the transparency problem plaguing most assessment programs. Everyone sees exactly where items sit in the workflow, why specific items got flagged, which reviewers consistently miss certain error types. This visibility naturally improves performance without heavy-handed management.
The governance model implementation sequence
Rolling out assessment governance requires careful staging. Programs that try implementing everything simultaneously usually trigger resistance and confusion.
Start with role clarity. Document who does what, even if your current process is messy. Make the implicit explicit. Often, just writing down current responsibilities reveals obvious problems.
Next, implement approval gates for new items only. Don't try retrofitting your entire item bank immediately. Let people adjust to the gate process with lower stakes before applying it universally.
Add SLAs once gates are running smoothly. Start with generous timelines, then tighten based on actual performance. Nothing kills buy-in faster than impossible deadlines on day one.
Finally, layer in quality metrics and lifecycle tracking. By this point, people understand their roles and the workflow. Adding measurement feels natural rather than punitive.
A corporate training division I guided through this sequence went from chaos to consistency in about 16 weeks. They started with 6 people wearing multiple unclear hats, no documented processes, and assessments that varied wildly in quality. The staged implementation let them maintain operations while gradually improving. They ended with clear accountability, 85% first-pass approval rates, and test reliability consistently above 0.82.
Beyond compliance: when governance drives innovation
Strong assessment governance doesn't just prevent problems—it enables capabilities impossible in chaotic environments.
With clear roles and workflows, you can experiment with new item types without risking quality. Your psychometrician can pilot adaptive testing while writers continue producing standard items. Reviewers can test new bias detection methods on subset populations.
Governance also enables meaningful continuous improvement. When everyone knows their metrics, they naturally optimize. Writers learn which patterns get rejected. Reviewers calibrate their standards. The entire system gradually improves without top-down mandates.
The real payoff comes in scalability. Programs with solid governance can double their test-taker volume with minimal stress. They can expand to new subject areas by simply adding specialized reviewers. They can meet new regulatory requirements by adjusting gates rather than rebuilding everything.
Making governance stick when people resist structure
The biggest barrier to assessment governance isn't technical—it's cultural. Academic environments especially resist anything resembling corporate process. "We're educators, not factory workers" is a phrase I hear regularly.
Frame governance as professional empowerment, not restriction. Writers get clear success criteria instead of vague feedback. Reviewers can focus on their expertise area instead of catching basic errors. Everyone spends less time in meetings figuring out what went wrong.
Start with voluntary adoption by your most frustrated team members. They're usually desperate for structure and become natural evangelists. Let their success stories convince skeptics rather than mandating compliance.
Also, acknowledge that governance needs flexibility. Building in exception processes for legitimate edge cases prevents people from feeling trapped by rigid rules. The structure should enable good judgment, not replace it.
Your assessment program's quality ultimately depends on having clear roles, efficient workflows, and consistent standards. The governance model outlined here provides that foundation while remaining adaptable to your specific context. Whether you're managing certification exams for thousands or course assessments for hundreds, these principles scale.
The choice isn't between informal flexibility and bureaucratic rigidity. It's between intentional structure that enables quality at scale and chaos that eventually forces crisis-driven reorganization. Every growing assessment program eventually implements governance—the question is whether you do it proactively or after something breaks badly enough that you have no choice.
Ready to revolutionize your evaluation process?
Join over 2,000 organizations using Evaloly to optimize assessments, improve learner outcomes, and make data-driven decisions.