

Ever watched a training manager explain why this year's certification scores dropped 12% compared to last year? "We updated the exam," they'll say. "Made it more relevant." Then comes the awkward silence when someone asks if the scores are actually comparable anymore.
This happens constantly across education and corporate training. A university updates their placement exam. An HR department refreshes their leadership assessment. A certification body modernizes their test questions. Each change makes perfect sense in isolation. But string together three years of these updates, and suddenly nobody knows if performance is actually improving or if you're just comparing apples to increasingly different oranges.
The real damage shows up in longitudinal reports. Those trend lines showing "improvement" over five years? Meaningless if version 2.3 of the assessment was 20% easier than version 1.0. That cohort comparison showing this year's new hires scoring lower? Could just mean the updated assessment emphasizes different competencies.
Most organizations handle assessment version control like they're managing a single Word document - save over the old one, maybe stick "v2" in the filename, call it done. That approach breaks the moment anyone needs to compare results across time periods or cohorts.
Why assessment versioning turns into chaos
Assessment updates follow a predictable pattern. Someone identifies a problem - maybe a question has become outdated, or pass rates seem off, or the content needs refreshing. A small committee makes changes. The updated version rolls out. Six months later, someone needs to compare results across versions and discovers nobody documented what changed or why.
A healthcare training organization I worked with had been using the same competency assessment for eight years. Except it wasn't really the same assessment. Digging through their files revealed at least fourteen informal updates. Some were minor wording tweaks. Others completely restructured entire sections. Nobody could definitively say which cohorts took which version.
The versioning problem compounds when multiple stakeholders get involved. The curriculum team wants to add new topics. The psychometrics team needs to maintain statistical properties. Legal wants to update compliance sections. IT needs everything to work in the testing platform. Each group makes sensible changes from their perspective, but the cumulative effect destroys comparability.
Traditional version numbering (1.0, 1.1, 2.0) captures none of this complexity. It doesn't tell you whether changes were cosmetic or fundamental. It doesn't indicate which cohorts are comparable. It definitely doesn't help when someone asks, "Can we compare the 2021 leadership cohort scores with this year's results?" and you realize one group took version 2.4 and the other took 3.1, with no documentation of what changed between versions.
The branching model that actually works
After watching dozens of assessment programs struggle with this, the pattern that consistently works mirrors software development branching - but adapted for the specific needs of assessment management.
Eliminate assessment bottlenecks.
Evaloly simplifies every step from test design to results analysis, making assessments faster and more reliable.
- Customizable test creation
- Automated grading and analytics
- Secure distribution and proctoring
No credit card required
Draft Branch
Every potential change starts here. No exceptions. Whether it's fixing a typo or redesigning half the assessment, it goes through draft status first. This creates a clear trail of what changed and why.
-
Change initiator and date
-
Specific modifications (item-level detail)
-
Rationale for each change
-
Expected impact on scores
Multiple draft versions can exist simultaneously. The math department might be updating quantitative questions while the writing team revises essay prompts. Each lives in its own draft branch until ready for pilot testing.
Pilot Branch
Drafts that pass initial review move to pilot status. This is where you test with real cohorts under controlled conditions. A pilot isn't just a beta test - it's a formal trial with specific data collection requirements.
-
Sample size and characteristics
-
Administration conditions
-
Preliminary psychometric data
-
Stakeholder feedback
-
Go/no-go decision criteria
The healthcare organization I mentioned started requiring minimum 100-person pilots for any substantial change. They run the pilot version alongside the current approved version with randomly selected test-takers. This generates direct comparability data before full rollout.
Approved Branch
Only assessments with completed successful pilots reach approved status. This is your production version - the one that generates official scores and appears in transcripts or employee records.
-
Effective date range
-
Applicable cohorts
-
Psychometric properties
-
Equating information (if applicable)
-
Sunset criteria
Multiple approved versions can coexist. You might have version 3.2 approved for North American cohorts while version 3.2-EU runs for European groups due to regulatory differences. The branching model handles this naturally.
Archived Branch
Assessments never truly die - they move to archived status. Archives maintain full functionality for historical score verification and research purposes.
-
Final administration date
-
Total cohorts assessed
-
Reason for retirement
-
Succession version mapping
-
Data retention requirements
This diagram shows the typical flow from draft to archived and how metadata and cohort mapping travel with each branch.
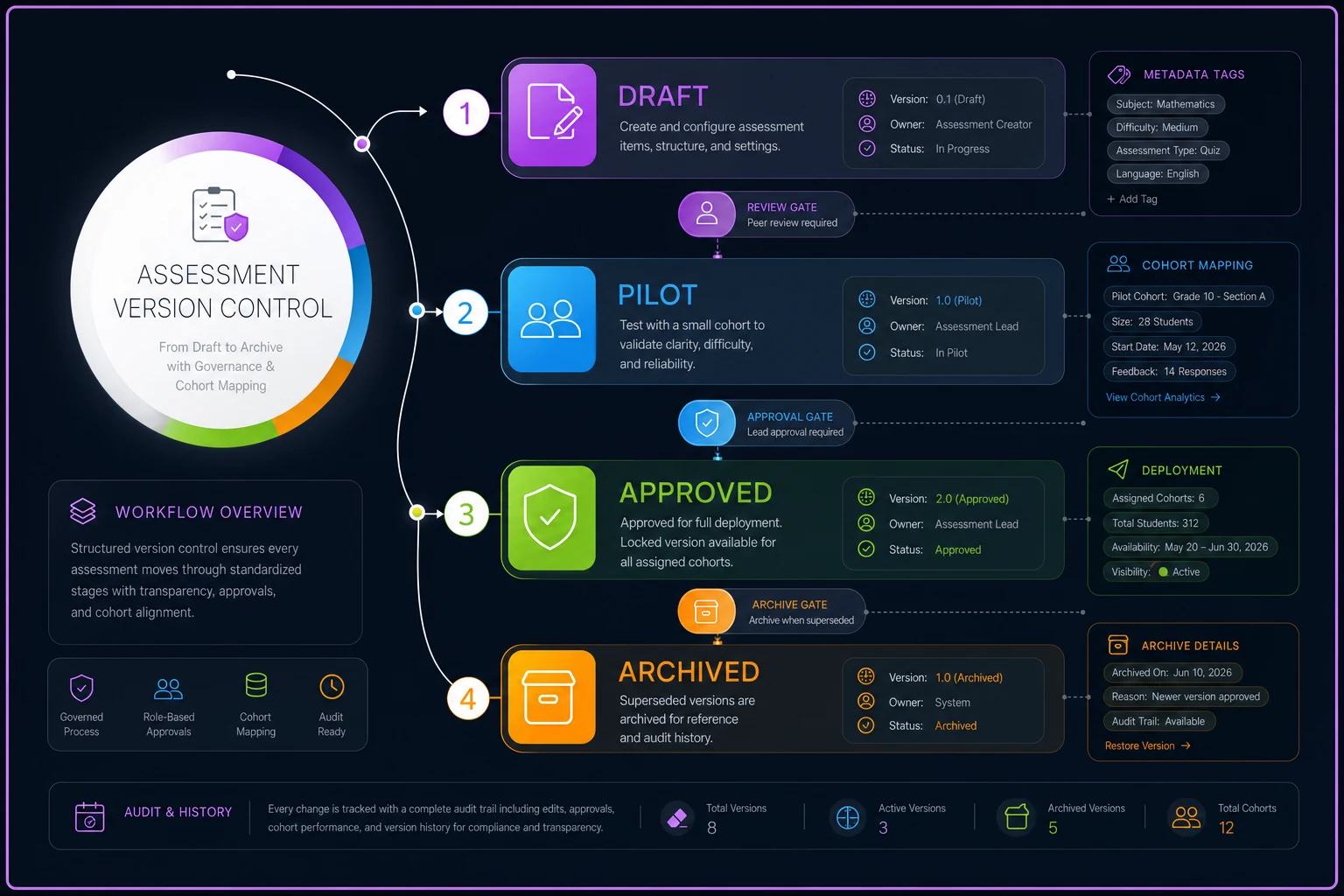
The graphic above summarizes the workflow and where pilots and approved versions sit relative to each other.
Metadata standards that prevent comparison disasters
The branching structure only works with rigorous metadata standards. Not the kind of metadata you'd track for a regular document - assessment metadata needs to support statistical comparisons across years and populations.
Essential Metadata Categories
Version Identity
-
Unique version ID (not just numbers)
-
Branch status (draft/pilot/approved/archived)
-
Parent version (what it's based on)
-
Child versions (what branched from it)
Change Documentation
-
Item-level change log
-
Addition/deletion/modification flags
-
Content vs. format changes
-
Statistical impact assessment
Cohort Mapping
-
Date ranges for each cohort
-
Sample sizes
-
Administration conditions
-
Population characteristics
-
Geographic/demographic segments
Psychometric Properties
-
Reliability coefficients by version
-
Validity evidence updates
-
Difficulty parameters
-
Discrimination indices
-
Standard error metrics
Comparison Flags
-
Direct comparability (yes/no/conditional)
-
Required equating procedures
-
Acceptable comparison cohorts
-
Statistical adjustment factors
The metadata lives alongside the assessment content, not in a separate system. When someone pulls version 2.4 for analysis, they automatically get the full context of what that version represents and how it relates to other versions.
Change logs that actually tell the story
Most change logs read like grocery lists: "Updated question 42. Revised instructions. Fixed typos." Useless for understanding whether versions are comparable.
Effective change logs for assessments need structure:
Question 27 Modification
-
Original
"Calculate the ROI for a $10,000 investment..."
-
Revised
"Calculate the ROI for a $10,000 initial investment..."
-
Type
Clarification
-
Impact
Minimal - adds precision but doesn't change difficulty
-
Comparability
Full - no adjustment needed
Question 31 Replacement
-
Original
Scenario about managing remote teams pre-2020
-
Revised
Updated scenario reflecting hybrid work realities
-
Type
Content modernization
-
Impact
Moderate - tests same competency but new context may affect difficulty
-
Comparability
Conditional - recommend equating study
Section 4 Restructure
-
Original
10 multiple choice items
-
Revised
5 multiple choice + 2 short response
-
Type
Format change
-
Impact
Major - changes time requirements and scoring approach
-
Comparability
None - requires separate norm tables
Each entry connects to specific cohorts, so you can instantly identify which groups took which version of each item. This granularity seems excessive until you're defending score differences to accreditors or explaining performance changes to executives.
Cohort tags for longitudinal analysis
The versioning system means nothing without proper cohort tagging. Every test administration needs consistent labeling that connects to the version hierarchy.
Standard cohort tag structure:
[Program]-[Year]-[Session]-[Version]-[Conditions]
Example: MBA-2024-Spring-v3.2-Standard
But tags alone don't enable comparisons. You need a comparison matrix:
| Cohort A | Cohort B | Comparability | Required Adjustment |
|---|---|---|---|
| MBA-2023-Fall-v3.1 | MBA-2024-Spring-v3.2 | Partial | Equating for items 15-22 |
| Cert-2023-Q1-v2.0 | Cert-2024-Q1-v4.0 | None | Different frameworks |
| Train-2024-Jan-v5.1 | Train-2024-Feb-v5.1 | Full | None |
The comparison matrix lives in the metadata system, automatically flagging when someone tries to compare incompatible cohorts or forgetting to apply necessary adjustments.
Real-world implementation example
A professional certification body with roughly 12,000 annual test-takers implemented this model after discovering their five-year trend reports were meaningless. They had been through four "minor updates" that cumulatively changed 60% of the assessment content.
Starting Point:
-
Single version number system (v1, v2, etc.)
-
Changes documented in email threads
-
No systematic cohort tracking
-
Comparison reports showing false trends
Implementation Process:
-
Historical Reconstruction (Months 1-2) They mapped every historical version they could identify. Found 11 distinct versions over 5 years, some used for just single quarters. Created retroactive cohort tags for 60,000+ historical test records.
-
Metadata Framework (Month 3) Built the metadata structure directly into their assessment management platform. Every assessment object now required: version ID, change log, cohort applicability, and comparison flags.
-
Pilot Process Testing (Months 4-5) Tested the draft→pilot→approved workflow with a minor update. Discovered their pilot sample calculations were too small for reliable statistics. Adjusted to require minimum 200 pilot testers for substantive changes.
-
Full Implementation (Month 6) Rolled out complete branching model. They maintained three approved versions simultaneously during transition: old version for retakes, current version for new testers, and pilot version for volunteers.
Results after 18 months:
-
Identified $180,000 in unnecessary remedial training triggered by non-comparable assessment versions
-
Reduced assessment update cycle from 8 months to 3 months
-
Eliminated post-hoc score adjustment controversies
-
Passed accreditation review with zero assessment validity concerns
The surprising discovery: their pass rates hadn't actually been declining. Version 3 was simply 15% harder than version 2, but nobody knew because change documentation didn't capture difficulty shifts.
When to implement version control (and when it's overkill)
This branching model makes sense when you run assessments for 500+ people annually, scores impact significant decisions (certification, placement, promotion), you need longitudinal tracking beyond 2 years, multiple stakeholders influence assessment updates, or regulatory requirements demand comparability evidence.
It's probably overkill for simple knowledge checks, purely formative assessments, situations where the same cohort never takes multiple versions, or when you rebuild assessments from scratch regularly anyway.
The middle ground: implement just the metadata standards first. Even without full branching, proper change documentation and cohort tagging solves most comparability problems.
Automated tracking with modern platforms
Manual version control breaks around 1,000 test-takers annually. Beyond that, you need platform-level automation. Modern assessment platforms increasingly build in version control, but most implement it poorly - treating assessments like documents rather than statistical instruments.
Automatic Cohort Assignment
When someone starts an assessment, the platform assigns them to the appropriate cohort based on date, program, and conditions. No manual tagging, no spreadsheet tracking.
Forced Change Documentation
Platform prevents saving changes without documenting what changed and why. Not a text box - structured fields that feed into comparison matrices.
Comparison Warnings
When generating reports across cohorts, platform checks compatibility and warns about comparison validity. Shows required adjustments or blocks invalid comparisons entirely.
Version Branching Workflows
Built-in draft→pilot→approved progression with approval gates. Can't accidentally deploy a draft version. Can't skip pilot phase for major changes.
Some platforms treat these as "enterprise features" with massive price jumps. Once you need version control, not having it costs more in bad decisions and rework than any platform upgrade.
For organizations running assessments through general-purpose survey or quiz tools - you're essentially building version control through naming conventions and spreadsheets. Works until it doesn't, usually during an audit or when someone important questions score validity.
Modern AI-powered operational software can automate much of this workflow. These platforms handle the version control branching automatically, enforce metadata requirements, and flag comparison issues before they become problems. The software catches what manual processes miss - like when someone tries to compare cohorts across incompatible versions or skips required pilot phases.
The assessment integrity payoff
Strong version control seems like administrative overhead until you face these situations:
An accreditor asks why pass rates dropped 8% year-over-year. With version control, you show exact changes, pilot data demonstrating increased difficulty, and psychometric evidence that standards actually increased. Without it, you're explaining with hand-waving and promises to "look into it."
An employee challenges their assessment score, claiming the test was harder than what their colleague took six months earlier. Version control shows both took version 4.2, with identical content and conditions. Complaint resolved with data, not arguments.
The board wants to know if the leadership development program is working - are participants actually improving over the five-year measurement period? Version control enables valid longitudinal comparison with appropriate statistical adjustments for version changes. You present real trends, not artifacts of assessment evolution.
A training vendor claims their program improved participant scores by 15%. Version control reveals participants took an easier assessment version post-training. Actual improvement: 3%. Saves a $400,000 contract renewal based on false success metrics.
Organizations using this model report 50-60% reduction in score challenges and 3x faster assessment updates due to clearer processes.
Making version control sustainable
The branching model fails when it becomes too complex for actual humans to follow. Keep it sustainable by limiting active branches - maximum three versions in production simultaneously. Any more creates confusion about which version to use when. Archive aggressively; if nobody's taken it in 6 months, it moves to archived status.
Schedule quarterly version reviews instead of continuous updates. Batch minor changes together. Exceptions only for critical errors or compliance requirements.
Assign clear ownership - one person owns version control decisions. Not a committee, a single accountable individual who approves progressions from draft to pilot to approved.
Use simplified pilot criteria: standard pilot requires 100 participants and 30 days, major revision pilot requires 250 participants and 60 days. No complex decision trees.
Conduct annual comparability audits. Review comparison matrices yearly - which cohorts are actually being compared? Are the statistical adjustments working? Prune unnecessary complexity.
The certification body mentioned earlier learned this the hard way. Their initial implementation included 12 different branch types and 47 metadata fields. After a year, they simplified to 4 branches and 18 essential metadata fields. Adoption improved immediately.
Start with cohort tagging if nothing else.
Assessment version control isn't about creating perfect documentation - it's about preventing broken comparisons that lead to bad decisions. Every organization running assessments at scale eventually faces the moment when someone asks, "Are these scores actually comparable?" Without proper version control, the honest answer is usually "we don't really know."
The branching model with metadata standards solves this by treating assessments as living instruments that evolve while maintaining their measurement integrity. Yes, it requires more structure than saving files with incremented version numbers. But the alternative - making decisions based on incomparable data - costs far more than any version control system.
Start with cohort tagging if nothing else. Just knowing which groups took which version solves half your comparison problems. Add change logs when you update assessments. Build toward the full branching model as your assessment program grows. The goal isn't perfect version control - it's defensible comparisons that support valid decisions.
Start with cohort tagging if nothing else. Just knowing which groups took which version solves half your comparison problems. Add change logs when you update assessments. Build toward the full branching model as your assessment program grows. The goal isn't perfect version control - it's defensible comparisons that support valid decisions.
Ready to revolutionize your evaluation process?
Join over 2,000 organizations using Evaloly to optimize assessments, improve learner outcomes, and make data-driven decisions.