

Your competency-based question bank probably started clean. Marketing competencies tagged here, technical skills mapped there. Six months later? Marketing questions show up in engineering assessments because someone tagged "communication" without context. Your promotion criteria pulls questions that test entry-level knowledge for senior positions. The whole system becomes unreliable right when you need it most—during critical hiring sprints or promotion cycles.
This breakdown happens in almost every assessment platform once you hit around 500 questions across 8-10 roles. The problem isn't the software. It's the lack of operational structure around how competencies get defined, tagged, and maintained as your organization evolves.
Why competency mapping breaks down
Most organizations approach competency mapping backwards. They start by creating questions, then try to retrofit tags and competencies afterward. By the time someone realizes the tagging system needs structure, you've got 800 questions with inconsistent labels spread across departments.
The engineering team uses "problem-solving" to mean debugging code. Sales uses the same tag for objection handling. HR pulls both into a leadership assessment, and suddenly your director candidates are answering questions about SQL queries.
This happens because competency-based question banks require three layers of structure that most teams never build:
First, role blueprints that define which competencies matter at which levels. Second, a controlled vocabulary that prevents tag sprawl. Third, mapping matrices that connect specific questions to competency levels within roles.
Without these three elements, your question bank becomes a junk drawer. Useful items exist somewhere inside, but finding the right combination for any specific assessment takes hours of manual filtering.
Building role blueprints that work
A functional role blueprint does more than list skills. It defines competency progression across levels and weights importance for decision-making.
Eliminate assessment bottlenecks.
Evaloly simplifies every step from test design to results analysis, making assessments faster and more reliable.
- Customizable test creation
- Automated grading and analytics
- Secure distribution and proctoring
No credit card required
Take a product manager progression. Entry level needs basic project coordination, stakeholder communication, and market research skills. Senior level requires strategic thinking, cross-functional leadership, and P&L management. But most blueprints miss the transition competencies.
Mid-level PMs need both coordination skills AND emerging strategic thinking. Your question bank should test for this hybrid state. Otherwise, you end up promoting coordinators who can't think strategically or rejecting strategic thinkers who haven't proven they can still execute details.
A partial blueprint for a customer success role:
| Level | Core Competencies | Weight | Transition Competencies | Weight |
|---|---|---|---|---|
| Junior CSM | Product knowledge, ticket resolution, documentation | 60% | Basic account analysis, escalation judgment | 40% |
| CSM II | Account management, renewal negotiations, QBR delivery | 50% | Strategic planning, cross-sell identification | 50% |
| Senior CSM | Portfolio strategy, team mentoring, process improvement | 40% | Revenue forecasting, executive relationships | 60% |
| CS Manager | Team performance, operational planning, stakeholder management | 70% | Department strategy, budget planning | 30% |
Notice how transition competencies increase in weight as you move up levels? That's intentional. Promotions fail when you test only for current-level mastery instead of next-level readiness.
Creating a tag vocabulary that scales
Tag sprawl kills assessment quality faster than any other operational failure. When "communication" has 47 variations across your question bank, finding appropriate questions becomes impossible.
The fix requires a three-tier tagging hierarchy:
-
Technical
-
Interpersonal
-
Business Operations
-
Leadership
Competency tags (specific skills within domains):
-
Technical → Python Programming
-
Technical → System Architecture
-
Interpersonal → Conflict Resolution
-
Interpersonal → Presentation Skills
Context tags (application specifics):
-
Python Programming → Data Analysis
-
Python Programming → Web Development
-
Conflict Resolution → Peer Disputes
-
Conflict Resolution → Customer Complaints
This hierarchy prevents the most common tagging mistake: over-specific initial tags that can't be reused. Instead of creating "Python-for-data-science-intermediate-level-pandas-library," you use three tags: Python Programming + Data Analysis + Intermediate.
But here's the operational requirement everyone misses: tag governance. Someone needs ownership of the vocabulary. Not committee ownership—single person ownership with a review process.
Assign single-person ownership of the tag vocabulary with a regular review process.
Without an owner, departments create their own tags. Marketing adds "content creation" while Engineering adds "documentation writing" for essentially the same competency. Three months later, you're running SQL queries trying to figure out why assessments are missing obvious questions.
Item-to-competency mapping matrices
The mapping matrix is where question banks either become powerful or fall apart. This isn't just linking questions to tags—it's defining how strongly each question tests each competency.
Most platforms support simple one-to-one mapping: Question A tests Competency B. But real assessment items rarely work that cleanly. A case study about handling an escalated customer might test conflict resolution (primary), product knowledge (secondary), and documentation skills (tertiary).
Your mapping matrix should capture these relationships with weights:
| Question ID | Primary Competency | Weight | Secondary Competency | Weight | Tertiary Competency | Weight |
|---|---|---|---|---|---|---|
| CS-147 | Conflict Resolution | 0.6 | Product Knowledge | 0.3 | Documentation | 0.1 |
| CS-148 | Technical Troubleshooting | 0.7 | Customer Communication | 0.2 | Escalation Judgment | 0.1 |
| CS-149 | Account Planning | 0.5 | Data Analysis | 0.3 | Stakeholder Management | 0.2 |
These weights matter during scoring. If a candidate struggles with CS-147, you know they primarily struggle with conflict resolution, not product knowledge. This granularity drives better development conversations and promotion decisions.
The matrix also enables competency gap analysis. Pull all questions that test "Data Analysis" as primary or secondary, and you can quickly identify if you have enough items to reliably assess that skill. Most organizations discover massive gaps this way—12 questions testing basic Excel skills, zero testing statistical interpretation.
Maintenance routines that prevent decay
Every competency-based question bank degrades without maintenance. Questions become outdated, tags drift from their original meaning, and new roles emerge without proper blueprint development.
The minimum viable maintenance schedule:
Quarterly tag audit (2-3 hours): Review all tags created in the past quarter. Merge duplicates, clarify definitions, and update the controlled vocabulary document. This prevents tag sprawl before it becomes unmanageable.
Semi-annual question review (by competency): Pick 2-3 high-volume competencies each cycle. Review every question tagged with those competencies. Check if the mapping still makes sense, if difficulty levels are accurate, and if content remains relevant.
Annual role blueprint updates (1-2 days per department): Roles evolve. The customer success manager who needed phone skills five years ago now needs video presentation abilities. Annual blueprint reviews catch these shifts before they affect promotion decisions.
Ongoing performance correlation (monthly): Track whether assessment scores predict job performance. If engineers who score high on your "system design" questions consistently struggle with actual system design work, your questions aren't testing what you think they're testing.
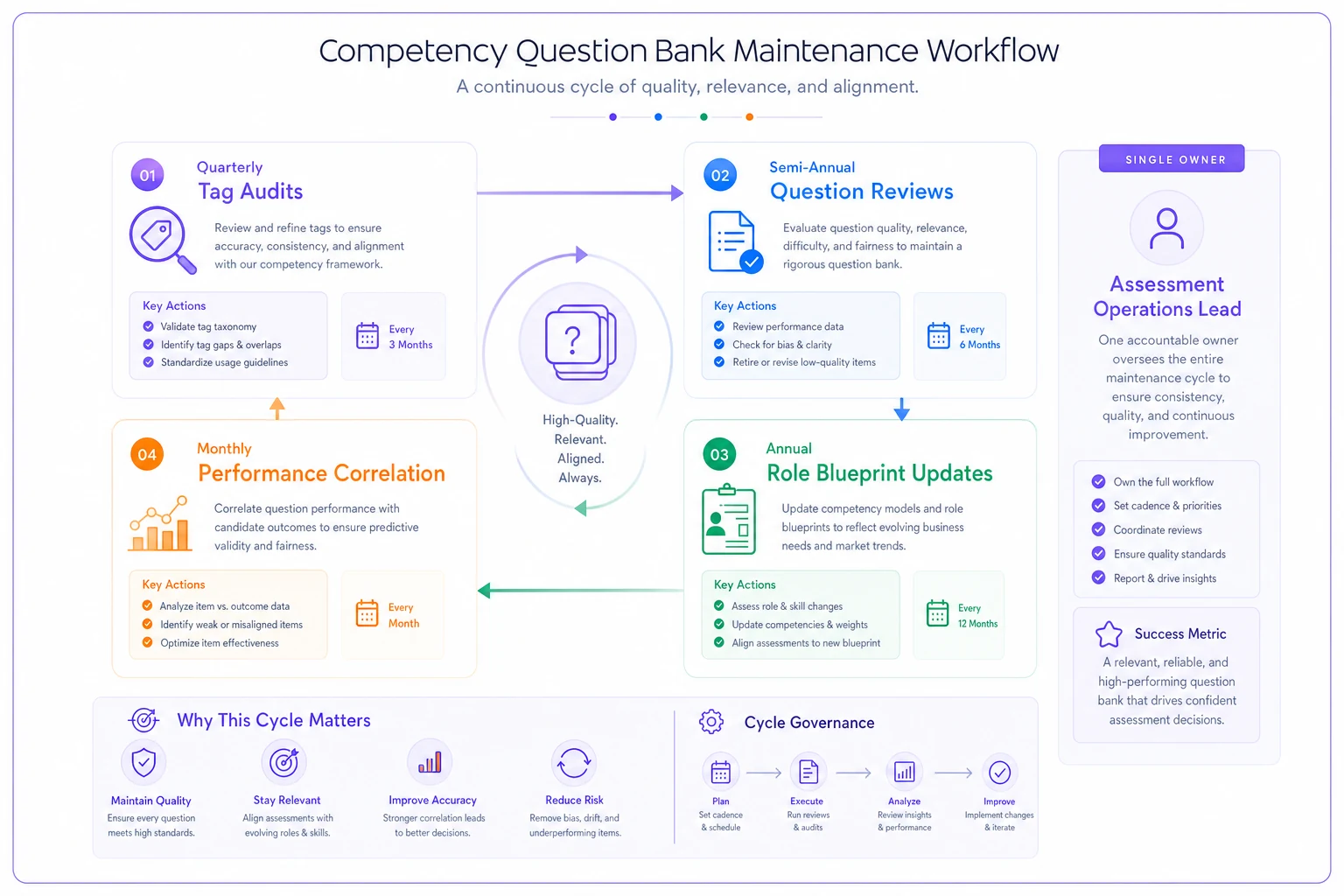
A visual like this makes the recurring steps clear and shows ownership at a glance.
Most teams miss this: maintenance needs to be someone's actual job responsibility, not a "when we get to it" task. The moment it becomes optional, it stops happening. Then six months later, you're explaining why the new VP hire who aced the assessment can't perform basic leadership functions.
When automation actually helps
AI-powered operational software transforms question bank management from a maintenance burden into a self-improving system. But automation works only when you have the foundational structure in place first.
Pattern detection across question performance shows which items consistently misalign with their tagged competencies. If questions tagged "analytical thinking" correlate more strongly with "technical knowledge" scores, the system flags them for review.
Auto-tagging suggestions based on question content reduce the manual work of classification. But these suggestions need human validation—the AI might correctly identify that a question tests "communication" but miss that it's specifically testing "technical documentation" versus "customer communication."
The real value comes from usage analytics. The system tracks which competencies get assessed most frequently, which have insufficient questions, and which roles lack proper coverage. Instead of discovering gaps during urgent hiring pushes, you see them months in advance.
Drift detection matters too. When hiring managers consistently override certain questions or manually add different ones, that signals blueprint misalignment. Maybe the role evolved, or maybe the original blueprint never matched reality.
Practical implementation timeline
Building this infrastructure while maintaining ongoing assessments requires staged rollout. Here's a realistic timeline that won't disrupt current operations:
Weeks 1-2: Define role blueprints for 2-3 critical roles. Pick roles with high hiring volume or upcoming promotion cycles. Don't attempt every role at once.
Weeks 3-4: Establish core vocabulary for those roles. Start with 30-40 terms maximum. You'll expand later, but starting small prevents early chaos.
Weeks 5-8: Map existing questions to the new structure. This reveals gaps immediately. You'll find competencies with two questions and others with forty.
Weeks 9-12: Create missing questions for gap areas. Focus on high-weight competencies first. A senior role missing leadership assessment items needs attention before optimizing entry-level coverage.
Week 13 onward: Expand to additional roles, following the same pattern. Each role takes less time as your vocabulary stabilizes and mapping patterns emerge.
The organizations that succeed with competency-based question banks treat them as operational infrastructure, not content libraries. They invest in structure, governance, and maintenance before worrying about volume.
Your assessment outcomes directly reflect this infrastructure quality. Strong foundations produce consistent, defensible hiring and promotion decisions. Weak foundations produce confusion, bias, and eventually, complete abandonment of competency-based assessment.
The choice comes down to this: invest three months building proper structure now, or spend years explaining why your assessments don't predict performance. Most organizations learn this lesson the expensive way—after a string of failed senior hires or mass exodus of promoted-but-unprepared managers.
Start with one role blueprint. Build it completely—competencies, tags, mappings, and questions. Prove the model works before expanding. The infrastructure you build today determines whether your competency-based question bank becomes a strategic asset or expensive mistake.
Ready to revolutionize your evaluation process?
Join over 2,000 organizations using Evaloly to optimize assessments, improve learner outcomes, and make data-driven decisions.