

Mixed-format assessments are killing grading efficiency.
You've got essays paired with multiple choice. Short answers mixed with coding problems. Case studies combined with calculations. Each format needs different evaluation approaches, different time investments, different quality checks.
Most educators and trainers handle this chaos through brute force—grading everything manually, burning through weekends, creating inconsistencies between tired Tuesday grading and fresh Friday reviews. HR managers running technical assessments face the same drain. Corporate trainers evaluating competency portfolios hit the same wall.
There's a third path beyond the binary choice of "automate everything and lose quality" versus "grade everything manually and burn out." Clear automation boundaries with human-in-the-loop triggers preserve quality where it matters most.
The mixed-format grading trap
Mixed-format assessments exist for good reasons. Multiple choice questions efficiently test breadth of knowledge. Essays reveal depth of understanding. Coding problems demonstrate practical application. Case analyses show judgment and reasoning.
But operationally? Mixed formats create workflow nightmares.
Consider a technical certification exam with 40 multiple choice questions, 3 coding challenges, and 2 written explanations. The multiple choice takes seconds per question to grade. The coding challenges need functional testing plus code review. The written explanations require careful reading for conceptual understanding.
One assessment. Three completely different grading workflows. Three different quality standards. Three different time requirements.
Now multiply that by 200 candidates.
The traditional approach fragments everything. Grade all the multiple choice first. Then tackle coding challenges. Finally push through written responses. By the time you circle back to provide feedback, you've lost context on individual performance patterns. Quality becomes inconsistent. Time compounds.
Why sampling beats exhaustive review
You don't need to manually review every single response to maintain quality.
Eliminate assessment bottlenecks.
Evaloly simplifies every step from test design to results analysis, making assessments faster and more reliable.
- Customizable test creation
- Automated grading and analytics
- Secure distribution and proctoring
No credit card required
Statistical sampling works for grading just like it works for quality control in manufacturing. Review a representative sample, establish confidence intervals, flag outliers for deeper review.
Take those 200 certification exams. Instead of manually reviewing all 600 coding challenges (200 candidates × 3 problems), you sample 20% randomly, plus any that automated checks flag as edge cases. If the sample shows consistent grading accuracy above 95%, you trust the automation for the rest. If accuracy drops below threshold, you expand the sample.
-
Random baseline sample (usually 10-20%)
-
Automatic inclusion of outliers (unusually high or low scores)
-
Triggered review for specific patterns (all students missing the same question)
-
Periodic calibration checks
A training organization I worked with reduced essay grading time by 60% using this approach. They manually graded every fifth essay completely, spot-checked specific rubric criteria on others, and flagged any essays with unusual score patterns for full review. Quality metrics actually improved because graders could focus attention where judgment mattered most.
When sampling, stratify by score bands to ensure errors at different performance levels are caught.
This applies proven quality control methodology to assessment workflows.
Building rubrics that enable partial automation
Most rubrics fail at the operational level because they're designed for humans, not hybrid workflows.
A traditional essay rubric might say "demonstrates critical thinking" or "shows mastery of concepts." These work fine for experienced graders but create automation bottlenecks. You can't partially automate subjective criteria.
Effective hybrid rubrics break evaluation into automatable and human-judgment components:
Automatable components:
-
Word count requirements
-
Citation formatting
-
Required section presence
-
Keyword/concept inclusion
-
Grammar and spelling thresholds
-
Code functionality tests
-
Calculation accuracy
Human-judgment components:
-
Argument coherence
-
Creative problem solving
-
Contextual understanding
-
Nuanced interpretation
-
Ethical reasoning
-
Strategic thinking
Consider a business case analysis worth 30 points. Instead of one holistic rubric, you create layers:
Automated layer (10 points):
-
Contains financial analysis section (2 points)
-
Includes 3+ cited sources (2 points)
-
Addresses all 5 required elements (3 points)
-
Meets 800-word minimum (1 point)
-
Uses proper business terminology (2 points)
Human review layer (20 points):
-
Quality of competitive analysis (5 points)
-
Feasibility of recommendations (5 points)
-
Strategic thinking demonstration (5 points)
-
Risk assessment depth (5 points)
The automation handles the mechanical checks instantly. Humans focus on the 20 points requiring judgment. Time per assessment drops from 15 minutes to 6 minutes while maintaining quality.
Human-in-the-loop triggers that work
Smart triggers create targeted human touchpoints.
Most platforms either automate everything (risking quality) or flag everything (defeating the purpose). The magic happens when you establish clear triggers for human intervention.
Score variance triggers: When automated scoring differs significantly from historical patterns, humans review. A student who normally scores 85% suddenly getting 40% triggers review. Not because the system failed, but because unusual patterns often indicate either technical issues or learning moments worth addressing.
Confidence threshold triggers: Natural language processing can score written responses with confidence ratings. Responses scoring below 70% confidence automatically route for human review. This catches edge cases, creative responses, and technical errors without manual review of everything.
Pattern detection triggers: When multiple assessments show identical unusual patterns—everyone missing question 7, similar phrasing in essays, clustered response times—the system flags for investigation. This catches everything from unclear questions to potential collaboration issues.
Fairness check triggers: Automated bias detection flags assessments showing score disparities across demographic groups beyond statistical norms. Humans investigate whether questions disadvantage certain populations or scoring algorithms need adjustment.
This saved a professional certification program from a lawsuit. Their automated scoring systematically rated international English speakers lower on communication assessments. The trigger caught it, humans identified culturally biased scoring criteria, and they fixed it before it impacted pass rates.
Time-savings reality check
Generic "save 50% of grading time" claims mean nothing without context.
| Assessment Component | Traditional Time | Hybrid Workflow Time | Method |
|---|---|---|---|
| 30 Multiple Choice | 7.5 minutes | 0 minutes | Fully automated |
| 5 Short Answers | 10 minutes | 2 minutes | Auto-scored with 20% sampling |
| 2 Essays | 16 minutes | 8 minutes | Rubric automation + human review |
| 1 Case Study | 12 minutes | 6 minutes | Structured scoring + human judgment |
| Total per Assessment | 45.5 minutes | 16 minutes | 65% reduction |
| 100 Assessments | 75.8 hours | 26.7 hours | 49.1 hours saved |
But raw time savings aren't everything. Consistency improves. Grader fatigue disappears. Quality metrics go up. Feedback becomes more detailed because graders have energy to write meaningful comments instead of just assigning scores.
The reduction varies by assessment type:
-
Technical assessments with objective components
70-80% time reduction
-
Essay-heavy humanities assessments
40-50% time reduction
-
Mixed professional certifications
55-65% time reduction
-
Complex case study evaluations
30-40% time reduction
The operational workflow determines whether these time savings materialize or evaporate.
Workflow orchestration specifics
Most organizations try to bolt automation onto existing processes. That fails. You need to redesign the workflow around automation boundaries.
Phase 1: Immediate automated processing As soon as submission closes, automated components run:
-
Multiple choice scoring
-
Keyword detection in written responses
-
Code compilation and testing
-
Plagiarism checking
-
Format compliance verification
-
Initial rubric scoring
This happens in minutes, not hours. Results populate dashboards immediately.
Phase 2: Sampling and triggered reviews Based on Phase 1 results, the system queues human reviews:
-
Random sample selection (stratified by score ranges)
-
Triggered reviews (outliers, low confidence, patterns)
-
Priority flagging (failing scores, high-stakes assessments)
Graders see a prioritized queue, not a pile of papers.
Phase 3: Human judgment and override Graders focus on:
-
Sampled responses for quality verification
-
Triggered cases requiring investigation
-
High-judgment rubric components
-
Override decisions on edge cases
-
Feedback writing for learning moments
Every human minute targets high-value evaluation.
Phase 4: Calibration and adjustment Post-grading analysis identifies:
-
Systematic scoring variations
-
Rubric components needing refinement
-
Automation accuracy rates
-
Grader consistency metrics
This feeds back into improving future cycles.
Here's a simple diagram showing the four phases and how data flows between automation and human review.
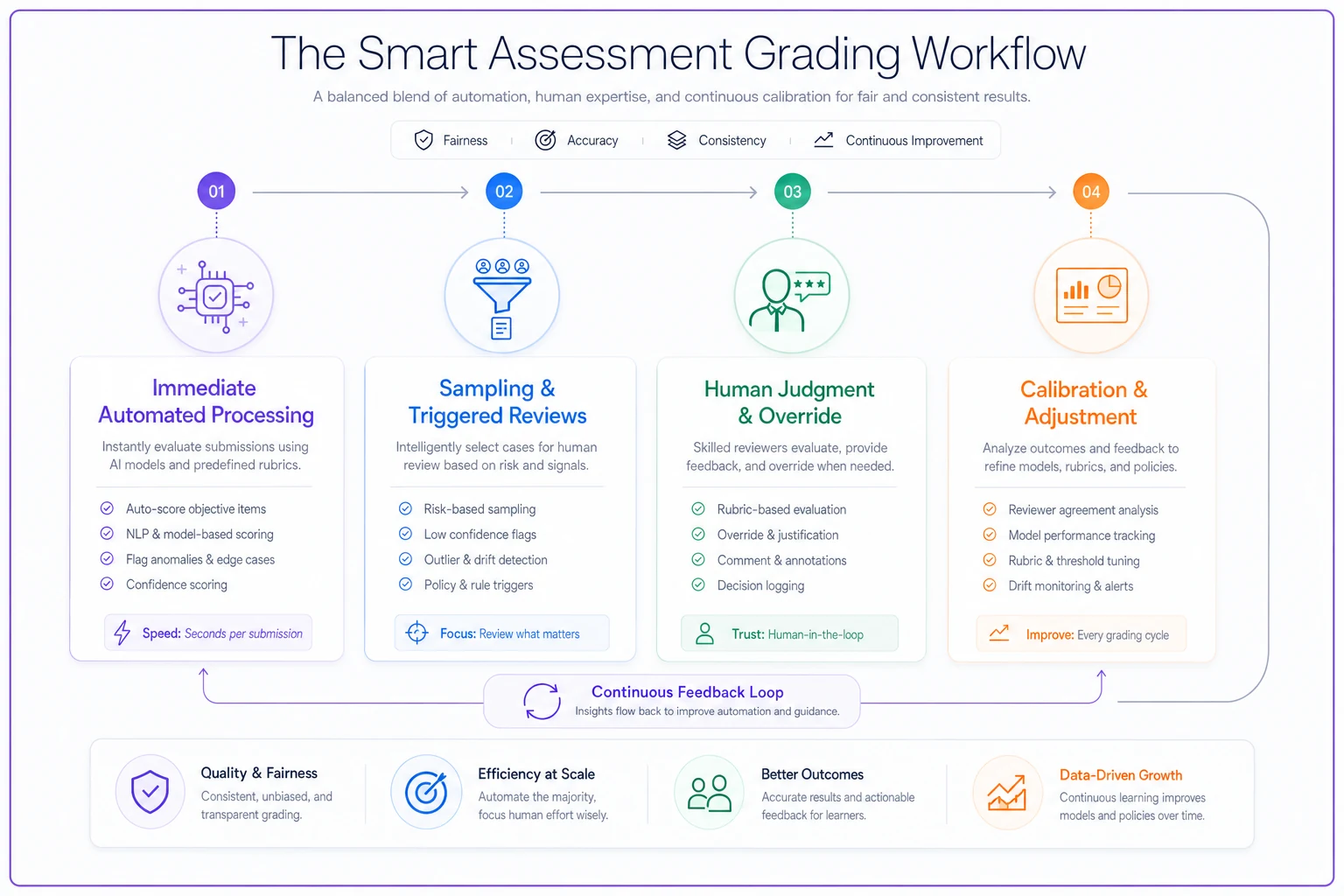
A corporate training team implemented this workflow for technical certifications. Previous manual process took 3 weeks from test close to results. New workflow delivers preliminary scores in 4 hours, final verified scores in 3 days.
Every cycle's data improved the next cycle's automation boundaries and reduced human workload.
Managing stakeholder expectations
The biggest implementation challenge isn't technical—it's human.
Students worry that automation means less thoughtful evaluation. Faculty fear being replaced. Administrators want cost savings without quality loss. Each group needs different messaging and proof points.
For students/candidates: Explain that automation handles mechanical checks so humans can focus on meaningful feedback. Show examples of detailed comments enabled by time savings. Emphasize that humans review all important decisions.
For faculty/graders: Position automation as eliminating grunt work, not replacing expertise. Demonstrate how it enables focus on high-value evaluation. Share workload reduction metrics that improve work-life balance.
For administrators: Present total cost of ownership including quality metrics. Show lawsuit risk reduction from consistency. Document time-to-results improvements. Calculate opportunity cost of delayed results.
Common resistance points:
-
"AI can't evaluate creativity"—Correct, which is why creative elements stay in human review while automation handles format checking.
-
"This will miss nuanced responses"—Confidence thresholds and sampling catch these for human review.
-
"Students will game the system"—Regular calibration and pattern detection prevent this.
-
"It's too complex to implement"—Phased rollout starting with simple components proves value.
Should you build custom grading automation or buy existing platforms?
Building versus buying automation boundaries
Should you build custom grading automation or buy existing platforms?
Building makes sense when you have:
-
Unique assessment formats
-
Specific regulatory requirements
-
Internal technical expertise
-
Budget for ongoing maintenance
-
Time for iterative development
Most organizations underestimate build costs by 3-5x. It's not just initial development—it's maintenance, updates, security, scaling, and feature evolution.
Buying makes sense when you need:
-
Quick implementation (under 3 months)
-
Proven reliability
-
Vendor support
-
Regular updates
-
Compliance documentation
The trap is buying platforms that force your assessments into their mold. Your mixed-format assessments become multiple-choice-only because that's what the platform handles well.
The sweet spot is platforms that provide frameworks for custom automation boundaries. You define rubrics, set triggers, establish sampling rules. The platform handles workflow orchestration, scaling, security.
Look for:
-
Flexible rubric builders
-
Customizable automation rules
-
API access for custom components
-
Human review interfaces
-
Analytics and calibration tools
-
Integration capabilities
A professional certification body spent two years trying to build custom automation. They switched to a configurable platform and went live in 10 weeks with better results than their custom build achieved.
Quality safeguards that scale
Small-scale manual grading has built-in quality checks—you notice if something seems off. Scaled automation can hide systematic issues until they explode.
Essential safeguards:
-
Inter-rater reliability monitoring Even with automation, track agreement between human reviewers on sampled items. Below 80% agreement triggers recalibration.
-
Automated anomaly detection Statistical models identify assessments with unusual score patterns for human review.
-
Periodic full manual audits Quarterly deep-dives on randomly selected complete assessments verify automation accuracy.
-
Candidate appeals process Clear escalation path for score challenges, with human review guaranteed.
-
Version control and rollback Every rubric change, automation rule, and trigger adjustment tracked with ability to revert.
A healthcare training program learned this lesson expensively. They automated competency assessments without safeguards. Six months later, discovered the automation had been incorrectly failing 15% of qualified candidates due to a rubric interpretation error. The lawsuits took years to resolve.
With proper safeguards, they would have caught the issue within days through sampling discrepancies.
Real implementation journey
A mid-sized university department actually implemented this system for their notorious qualifying exams.
Starting point: 400 graduate students taking comprehensive exams twice yearly. Mixed format with 60 multiple choice, 10 short answers, 4 essays. Three faculty graders spending 3 full weeks grading each cycle. Consistency issues between graders. Results delayed 6 weeks.
Month 1-2: Assessment redesign Restructured rubrics into automatable and human components. Identified which questions tested recall versus synthesis. Created detailed scoring guidelines for each component. Established inter-rater reliability baselines.
Month 3: Platform selection and configuration Evaluated 4 platforms against requirements. Selected based on rubric flexibility and workflow customization. Configured initial automation rules conservatively. Set up sampling at 30% for first cycle.
Month 4: Pilot with previous exams Ran historical exams through new system. Compared automated scores with manual grades. Identified and fixed systematic variations. Refined confidence thresholds.
Month 5: First live implementation Processed current exam cycle. Automated components completed in 2 hours. Human review of samples and triggers took 4 days. Results delivered in 1 week (previous: 6 weeks).
Month 6-8: Refinement Reduced sampling to 20% based on accuracy metrics. Added pattern detection for common misconceptions. Improved feedback templates. Fine-tuned automation boundaries.
Results after one year:
-
Grading time
3 weeks → 4 days
-
Inter-rater reliability
72% → 91%
-
Student satisfaction with feedback
increased 40%
-
Faculty grading burden
75% reduction
-
Cost per assessment
60% reduction
Starting conservatively and building confidence through data made the difference.
Making the math work for your context
Every organization needs different ROI calculations.
For educational institutions: Faculty hour cost runs $75-150/hour. Current grading time multiplied by hourly cost gives baseline expense. Automation investment includes platform cost plus setup time. Breakeven usually happens within 2-3 terms.
For corporate training: Delay cost means lost productivity while awaiting results. Quality cost includes incorrect pass/fail decisions. Compliance risk encompasses inconsistent evaluation standards. Breakeven often happens immediately for high-volume programs.
For certification bodies: Manual grading costs $20-50 per assessment. Automation costs $5-15 per assessment after setup. Volume threshold sits around 500+ assessments yearly. Breakeven typically occurs within 6-12 months.
Don't ignore soft costs:
-
Grader burnout and turnover
-
Delayed feedback impact on learning
-
Inconsistency reputation damage
-
Scalability constraints on growth
One certification body discovered their manual grading was constraining growth—they could only run exams quarterly due to grading capacity. Automation enabled monthly testing, tripling revenue without tripling costs.
When NOT to automate mixed-format grading
Automation boundaries aren't universally applicable.
Skip this approach when:
-
Volume doesn't justify investment Below 200 assessments yearly, manual grading often remains more cost-effective unless you're planning growth.
-
Assessments change constantly If you redesign assessments every cycle, automation setup becomes perpetual overhead.
-
Extreme subjectivity dominates Creative writing workshops, art portfolios, or philosophical arguments may need full human evaluation.
-
Regulatory prohibition exists Some accreditation or certification standards explicitly require human grading.
-
Trust hasn't been established New programs need manual grading to build stakeholder confidence before introducing automation.
Mixed-format assessment grading doesn't have to destroy your weekends or your budget.
The path forward
The solution isn't choosing between full automation and full manual review. It's establishing intelligent boundaries—automating what makes sense, sampling for quality assurance, and focusing human expertise where judgment matters.
Start small. Pick one assessment component to partially automate. Measure the impact. Build confidence. Expand gradually.
Your next mixed-format assessment cycle could take 65% less time with better consistency and richer feedback. The bottleneck isn't technology—it's deciding to move beyond the pure manual approach that's burning out your team and constraining your growth.
Your next mixed-format assessment cycle could take 65% less time with better consistency and richer feedback. The bottleneck isn't technology—it's deciding to move beyond the pure manual approach that's burning out your team and constraining your growth.
Ready to revolutionize your evaluation process?
Join over 2,000 organizations using Evaloly to optimize assessments, improve learner outcomes, and make data-driven decisions.