

Three months ago, a tech startup asked me to review their engineering hiring process. They'd been using a coding test they found online, tweaking interview questions based on gut feel, and wondering why half their new hires weren't working out. Their assessment process looked reasonable on paper—technical test, behavioral interview, culture fit discussion. But when we dug into their actual measurement approach, every single assessment violated basic validity principles. They were essentially flipping coins while convinced they had a scientific process.
This happens everywhere. School districts blow millions on assessment platforms that measure the wrong things. HR departments create elaborate competency frameworks that don't predict job performance. Training programs measure satisfaction scores instead of skill transfer. The tools look sophisticated, but the measurement underneath is broken.
Most educators, HR managers, and trainers never learned psychometric principles. They shouldn't need a statistics degree to make good assessment decisions. Without understanding measurement fundamentals though, assessments become expensive guessing games that waste resources and make terrible decisions about people's futures.
The validity problem hiding everywhere
Validity sounds academic until you realize it asks a simple question: does this assessment actually measure what matters for success? Most organizations never examine this question seriously. They inherit assessment practices, copy what competitors do, or trust vendor marketing claims.
A retail chain I worked with discovered their customer service assessment had zero correlation with actual customer satisfaction scores. For two years, they'd been hiring based on a test that measured typing speed and product knowledge but ignored emotional regulation and problem-solving under pressure. The assessment looked professional—timed sections, scoring rubrics, detailed reports. But it measured the wrong things.
-
List three specific things top performers do differently
-
Check if your assessment directly measures those behaviors
-
Look at your last 20 assessment decisions—how many succeeded?
-
Ask five high performers if the assessment reflects their actual work
-
Compare assessment scores to real performance after 6 months
When organizations run this audit, they usually discover their assessments measure academic knowledge, test-taking ability, or interview skills—not the actual competencies that drive performance.
Reliability problems destroy decision quality
Reliability means getting consistent results. If someone takes your assessment today and next week, they should score roughly the same. If two evaluators review the same work, they should reach similar conclusions. Sounds obvious, but most real-world assessments are wildly unreliable.
Eliminate assessment bottlenecks.
Evaloly simplifies every step from test design to results analysis, making assessments faster and more reliable.
- Customizable test creation
- Automated grading and analytics
- Secure distribution and proctoring
No credit card required
A manufacturing company tracked their safety certification tests over six months. The same employees taking similar tests scored anywhere from 65% to 92%. Not because their knowledge changed dramatically, but because the assessments themselves were unstable. Questions varied wildly in difficulty. Scoring depended on who graded them. Environmental factors like testing room, time of day, and computer problems introduced random noise.
-
Use multiple shorter assessments instead of one long test
-
Create detailed scoring guides with specific examples
-
Have two people independently score a sample—if they disagree significantly, your rubric needs work
-
Test the same core skills multiple ways
-
Remove questions that produce wildly different results
-
Document environmental standards (quiet room, standard timing, same instructions)
The goal isn't perfect reliability—that's impossible with humans involved. Moving from 40% to 75% consistency transforms decision quality though.
The fairness trap most organizations fall into
Fairness in assessment goes beyond avoiding obvious bias. It means ensuring the assessment gives everyone an equal opportunity to demonstrate their capabilities. Most organizations focus on surface-level fairness while ignoring systematic advantages that skew results.
Consider this scenario: A hospital system used a nursing competency exam that included multiple-choice questions about medical procedures, timed medication calculations, and written care plans. Seemed fair—everyone got the same test. But pass rates varied dramatically by background. Not because of nursing ability, but because the test format favored specific educational experiences.
-
Sales assessments that favor extroverted presentation styles over relationship-building approaches
-
Technical interviews that reward algorithm memorization over practical problem-solving
-
Leadership assessments that mistake confidence for competence
-
Training evaluations that measure retention instead of application
When they switched to performance-based assessments using simulated patient interactions, the gaps nearly disappeared. The original test wasn't measuring nursing ability—it was measuring test-taking skills shaped by educational background.
| Assessment Stage | Hidden Bias Risk | Quick Check Method |
|---|---|---|
| Design Phase | Cultural assumptions in scenarios | Review with diverse stakeholders |
| Delivery Method | Technology access, time constraints | Offer multiple format options |
| Scoring Process | Subjective interpretation | Compare scores across evaluator demographics |
| Decision Rules | Arbitrary cutoff scores | Examine pass rates by subgroup |
| Feedback Loop | Who gets development opportunities | Track post-assessment support distribution |
This pattern repeats across industries:
Converting measurement theory into everyday practice
The gap between psychometric theory and operational reality doesn't have to exist. You can build assessment systems that are valid, reliable, and fair without becoming a statistician. The key is translating abstract principles into concrete operational rules.
Never use a single data point for high-stakes decisions.
-
Never use a single data point for high-stakes decisions. Every promotion, termination, or certification required at least three different assessment methods. This naturally improved reliability without any statistical knowledge.
-
Match the assessment to the work. Customer service roles got assessed through recorded customer interactions. Technical roles through actual problem-solving. Leadership through team scenarios. Validity improved because assessments looked like real work.
-
Document why things predict success. For every assessment component, they required a one-sentence explanation of why it predicted job performance. If you couldn't explain the connection simply, the component got removed.
-
Track decisions for six months. Every assessment decision got a simple follow-up: did this person succeed? Patterns emerged quickly. The SQL test didn't predict database administrator success, but the troubleshooting simulation did.
These guardrails took their quality hire rate from around 55% to 78% within a year. Not through sophisticated psychometrics, but through disciplined application of measurement fundamentals.
Building your assessment quality checklist
Most assessment failures aren't dramatic—they're accumulations of small measurement mistakes. A slightly invalid test here, an unreliable scoring method there, some unexamined bias throughout. These compound into systems that look professional but produce random results.
Here's a practical checklist that catches most measurement problems before they become expensive mistakes:
Pre-Assessment Design
-
Define success in observable behaviors, not abstract qualities
-
Identify 3-5 critical incidents that separate high from low performers
-
Choose assessment methods that directly sample those behaviors
-
Create scoring criteria before seeing any responses
-
Test with a small group and check if results match their known performance
During Assessment Delivery
-
Standardize instructions, timing, and environment
-
Offer accommodations that don't compromise what you're measuring
-
Document any deviations from standard protocol
-
Use multiple raters for subjective assessments
-
Collect process feedback from participants
Post-Assessment Analysis
-
Compare scores across different demographic groups
-
Check if similar candidates get similar scores
-
Track correlation with actual performance metrics
-
Review edge cases and appeals for patterns
-
Calculate the cost of false positives vs false negatives
This checklist won't make you a psychometrician, but it catches most measurement problems that plague typical assessment programs. Building assessment quality checkpoints into AI-powered operational software makes this systematic rather than dependent on human memory.
When quick diagnostic tools actually work
Not every assessment needs rigorous validation studies and reliability coefficients. Sometimes you need quick diagnostic tools that are "good enough" for low-stakes decisions. Knowing when approximation is acceptable versus when precision matters makes all the difference.
Quick diagnostics work well for:
-
Initial screening before investing in comprehensive assessment
-
Formative feedback during learning
-
Self-assessment for development planning
-
Team discussions about general strengths
-
Identifying areas for further investigation
They fail catastrophically for:
-
Final hiring decisions
-
Certification or credentialing
-
Performance ratings tied to compensation
-
Academic placement decisions
-
Legal or compliance requirements
A software company developed what they called "confidence intervals for humans"—simple rules for interpreting quick assessment results:
The sampling problem everyone ignores
Statistical sampling sounds complex, but the core idea is simple: you can't measure everything, so you need smart ways to pick what you do measure. Most assessments fail because they sample the wrong things or too few things.
A college nursing program discovered their clinical evaluation sampled only routine procedures. Students who excelled at following protocols scored high. Students with exceptional critical thinking but average protocol execution scored lower. When actual nursing jobs required 70% problem-solving and 30% routine procedures, their assessment sampling was backward.
Improving sampling without statistical training:
-
List all important skills/knowledge areas
-
Estimate how much time people spend on each (percentages)
-
Count how many assessment items measure each area
-
Compare assessment weight to real-world importance
-
Adjust sampling to match reality
For example, if customer service reps spend 60% of their time de-escalating upset customers, but your assessment only includes 10% conflict resolution, you're sampling wrong.
The Critical Incident Technique
-
What situations separate great from good performance?
-
When do people typically fail in this role?
-
What decisions have the biggest downstream impact?
-
Which skills are hardest to develop after hiring/admission?
Sample heavily from these critical areas rather than spreading assessment thin across all possible topics.
Making interpretation actually actionable
Raw scores mean nothing without context. An 82% tells you nothing about whether someone should be hired, promoted, or needs development. Most organizations either use arbitrary cutoff scores or complicated statistical norm tables. Both approaches fail in practice.
Criterion referencing: What score indicates readiness for specific responsibilities? A regional bank discovered that loan officers scoring above 75% on their risk assessment test had 90% fewer default issues. That 75% meant something concrete—ready for independent loan approval.
Growth referencing: How much did this person improve? A call center tracked assessment scores monthly. Agents improving 10+ points per month typically became top performers within six months, regardless of starting score.
Comparative referencing: How does this score compare to successful people in similar contexts? Not generic norms, but specific comparison groups that make sense for your decision.
Practical interpretation framework that actually helps make decisions:
| Score Range | Interpretation | Typical Action |
|---|---|---|
| Bottom 20% | Significant gaps in critical areas | Intensive support or different role |
| 20-40% | Notable weaknesses affecting performance | Targeted development plan |
| 40-60% | Mixed readiness, some concerns | Additional assessment or probationary period |
| 60-80% | Solid foundation with growth areas | Standard onboarding/development |
| Top 20% | Ready for advanced responsibilities | Fast track or stretch assignments |
The key insight: interpretation rules should connect directly to actions. If a score doesn't change what you do, why measure it?
Technology and measurement fundamentals
Modern assessment platforms promise to handle measurement complexity for you. AI-powered screening, automated scoring, predictive analytics—the technology looks impressive. But fancy tools built on bad measurement foundations just fail faster and more expensively.
A Fortune 500 company implemented an AI recruitment platform that analyzed video interviews. The system scored candidates on hundreds of micro-behaviors: eye contact, speech patterns, facial expressions, word choice. The vendor claimed 94% predictive accuracy. Six months later, they discovered the AI mostly detected whether candidates had good webcams and quiet backgrounds. It was a very expensive way to measure socioeconomic status.
-
What specific construct does this measure, in plain language?
-
How do you know the measurement is valid for our context?
-
What happens when the tool fails or gives unclear results?
-
Can we audit and adjust the scoring logic?
-
How do we detect when the tool starts degrading?
The best organizations use technology to enhance human judgment, not replace it. Automated screening identifies candidates worth deeper review. AI scoring flags unusual patterns for human investigation. Predictive models suggest areas for additional assessment. AI-powered operational software can build these quality checks directly into assessment workflows, automatically flagging inconsistencies or bias patterns that humans might miss.
Building assessment systems that improve over time
Static assessment systems degrade quickly. Jobs evolve, populations change, and yesterday's valid measurement becomes today's expensive mistake. Most organizations treat assessments as "set and forget" infrastructure.
A simple continuous improvement system:
-
Monthly Review outliers and edge cases. Why did high scorers fail? Why did low scorers succeed? Each exception teaches something about measurement gaps.
-
Quarterly Compare assessment predictions to actual outcomes. Calculate hit rates, false positives, and false negatives. Look for drift in validity.
-
Annually Refresh critical incident analysis. Survey high performers about changed requirements. Update scoring based on accumulated evidence.
-
Continuously Collect participant feedback. Track completion rates, complaint patterns, and confusion points. Small frustrations often signal measurement problems.
Here's a simple workflow for continuous improvement in assessment systems:
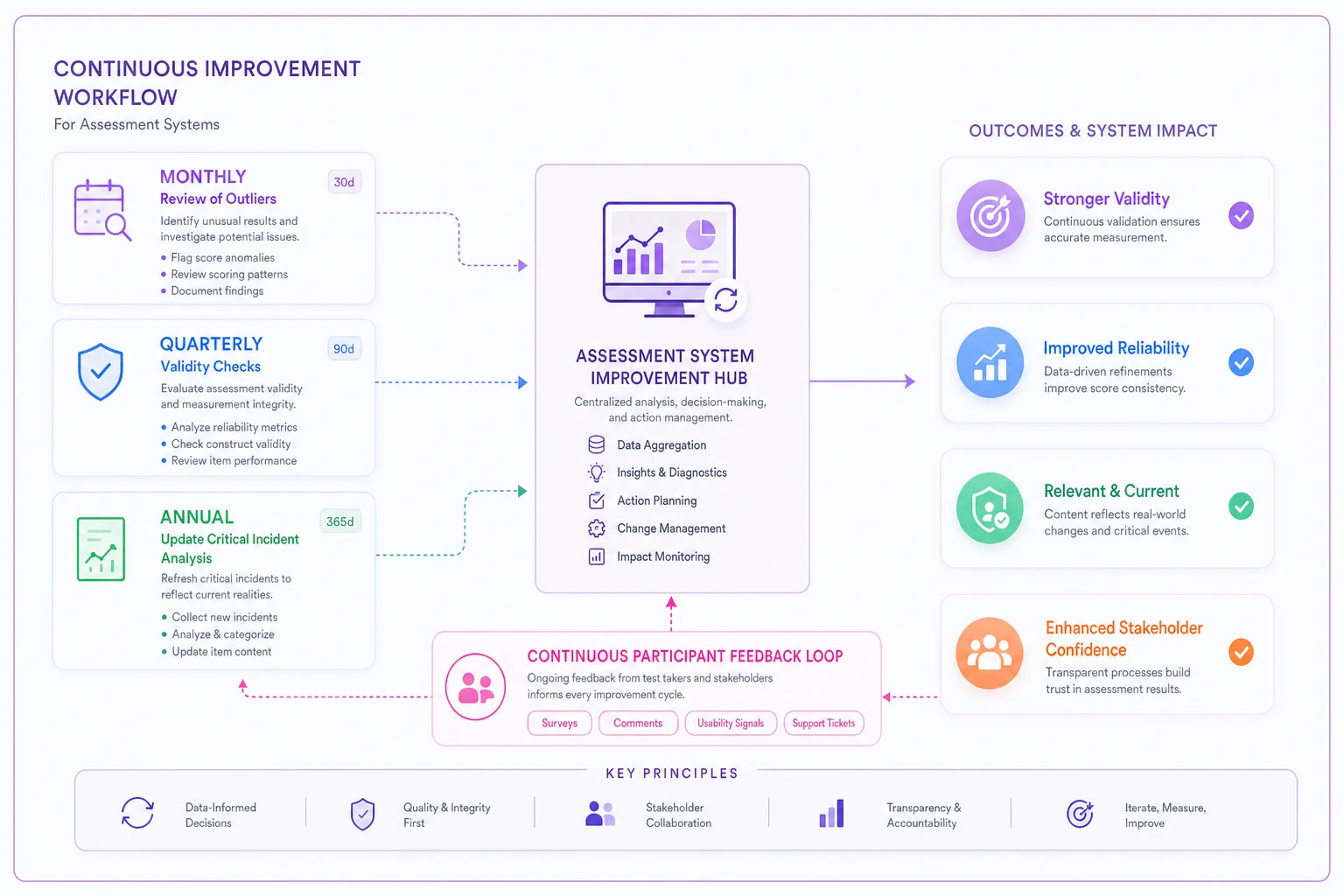
This doesn't require a measurement team—just discipline about capturing and reviewing data. A school district automated this by adding three questions to their existing performance reviews: Did initial assessment accurately predict performance? What important skills weren't assessed? What was assessed but doesn't actually matter?
Measurement as operational infrastructure
Measurement fundamentals aren't academic exercises—they're operational infrastructure as critical as your financial systems or production processes. Bad measurement creates compound waste: wrong hires, failed training investments, missed talent, legal risks, and destroyed trust. Good measurement becomes a competitive advantage: better talent decisions, effective development, fair advancement, and confident operations.
Start with one assessment that matters to your organization. Run the validity audit. Check reliability. Examine fairness. Build simple improvement loops. The compound effect of better measurement decisions will transform how your organization identifies, develops, and deploys talent.
Remember: you're not trying to become a psychometrician. You're trying to make assessment decisions that are demonstrably better than guessing. That bar is lower than you think, and clearing it consistently creates remarkable competitive advantage in any talent-dependent organization.
Ready to revolutionize your evaluation process?
Join over 2,000 organizations using Evaloly to optimize assessments, improve learner outcomes, and make data-driven decisions.