

Assessment teams adopting AI tools face an uncomfortable reality: the technology that promises to streamline operations can become a compliance nightmare faster than you'd expect. Not because AI is inherently broken, but because most organizations rush into implementation without establishing any governance framework first.
The chaos usually starts small. A training coordinator uses ChatGPT to generate quiz questions. An HR manager experiments with resume screening. A teacher tries automated essay grading. Each person solving their own immediate problem, completely unaware they're creating audit trails that could trigger discrimination claims, validity challenges, or regulatory issues months later.
What makes AI governance for assessments particularly tricky is that traditional compliance frameworks weren't built for this. Your existing assessment policies probably cover test security, accommodation procedures, and scoring protocols. They almost certainly say nothing about algorithmic transparency, model drift monitoring, or differential impact analysis across AI-generated content.
The governance gap between AI capability and assessment validity
Most assessment professionals understand measurement fundamentals like validity and reliability. They know how to design rubrics, analyze item performance, and ensure fair testing conditions. AI introduces a layer of complexity that traditional psychometric training doesn't really address.
Consider what happens when an organization starts using AI for item generation. The technology can produce hundreds of test questions in minutes—each grammatically correct and topically relevant. But without governance controls, you might discover months later that the AI consistently generates harder math problems when prompted about engineering assessments versus nursing assessments. Or that essay prompts subtly favor certain cultural references. These aren't intentional biases. They're artifacts of training data manifesting in ways that quietly compromise fairness.
The disconnect becomes obvious when you trace actual workflow failures. A corporate training department deployed an AI writing assessment tool that seemed fine during pilot testing. Six months later, they found the tool was scoring technical writing from non-native English speakers systematically lower—not because of actual quality differences, but because the model had associated certain grammatical patterns with lower scores. By then, promotion decisions had already been made.
This pattern repeats across industries because organizations treat AI governance as a technical problem rather than an operational one. They focus on model accuracy metrics while ignoring human review processes, documentation requirements, and bias detection protocols—which are what actually determine whether AI helps or hurts assessment quality.
Building operational guardrails that actually work
Effective AI governance starts with permitted use policies that people can actually follow. Not lengthy legal documents. Clear operational guidelines that specify which AI tools can be used for which assessment tasks.
Eliminate assessment bottlenecks.
Evaloly simplifies every step from test design to results analysis, making assessments faster and more reliable.
- Customizable test creation
- Automated grading and analytics
- Secure distribution and proctoring
No credit card required
The framework should distinguish between low-risk and high-risk applications. Using AI to format multiple choice questions or check grammar? Low risk. Using AI to generate performance assessment scenarios or score open-ended responses that affect employment decisions? High risk, requiring additional controls.
A practical permitted use matrix looks something like this:
| Assessment Task | AI Use Level | Required Controls | Review Threshold |
|---|---|---|---|
| Item formatting | Fully permitted | Basic output check | Random 5% sample |
| Grammar checking | Fully permitted | None required | None |
| Item generation (factual) | Permitted with review | Subject expert validation | 100% human review |
| Item generation (scenario) | Restricted use | Bias testing required | 100% review + testing |
| Automated scoring (objective) | Permitted with audit | Accuracy monitoring | Monthly validation |
| Automated scoring (subjective) | High restriction | Full documentation | 100% dual review |
| Candidate screening | Restricted use | Legal review required | Ongoing monitoring |
The key is making these guidelines operational, not aspirational. Each permitted use needs clear workflows showing who reviews AI outputs, what they're checking for, and how exceptions get escalated.
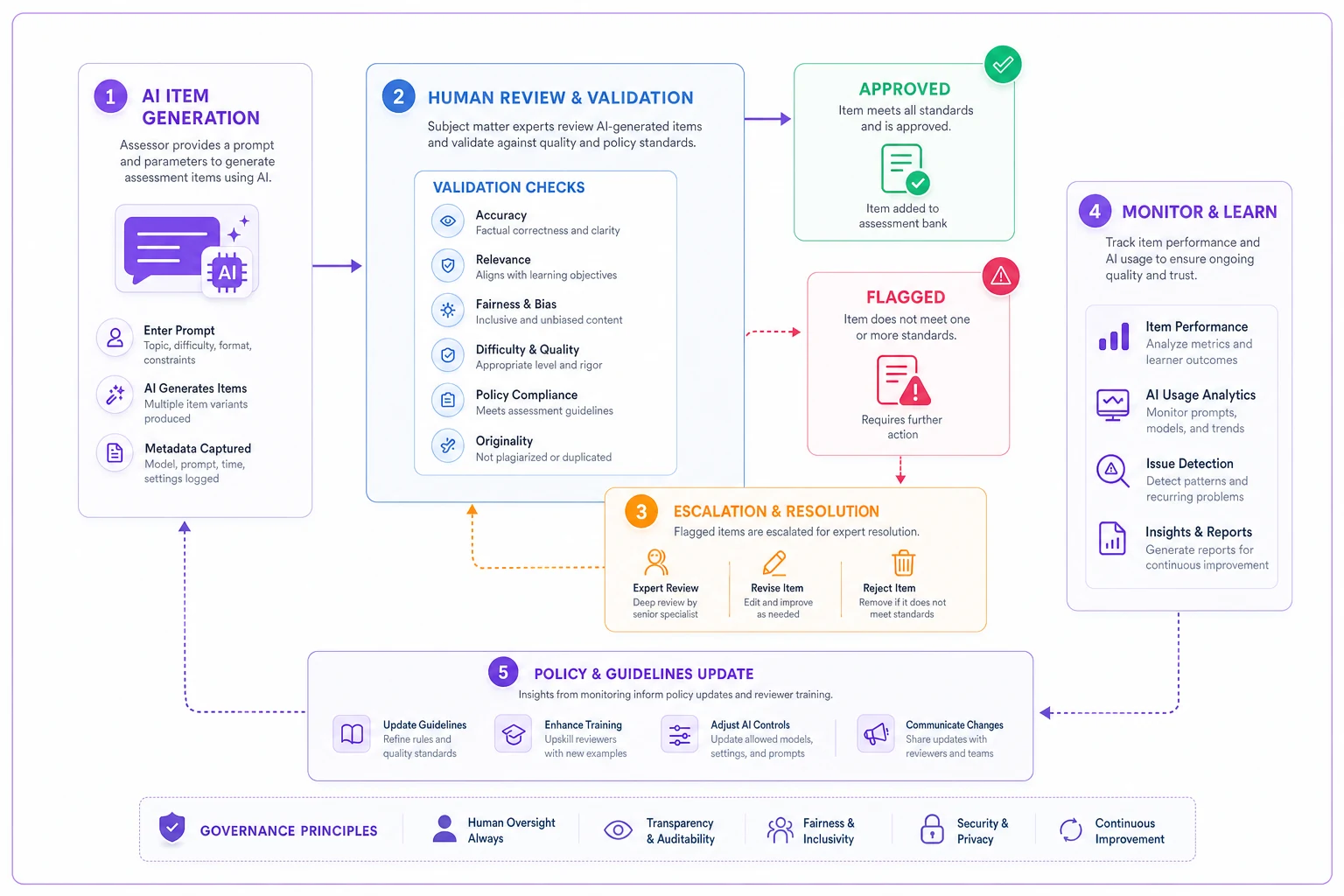
Visualizing the review and escalation steps makes it easier to standardize who does what and when.
Human review thresholds that balance efficiency and risk
Setting human review thresholds requires understanding both assessment stakes and operational capacity. Organizations that get this wrong either review everything—defeating the purpose of AI efficiency—or review nothing, creating massive blind spots.
Smart threshold setting starts with risk stratification. A practice quiz for internal training doesn't need the same scrutiny as a certification exam. But thresholds can't just be about test importance. They need to account for AI uncertainty signals too.
When AI generates test items, the review threshold might vary based on:
-
Confidence scores from the model
-
Similarity to existing validated items
-
Complexity of the content domain
-
Historical error rates for similar items
-
Regulatory requirements for the assessment type
A healthcare certification program learned this the hard way after setting blanket 20% review thresholds across all AI-generated items. They caught formatting errors in straightforward anatomy questions but missed subtle inaccuracies in complex pharmacology scenarios because those happened to fall outside their random sample.
Use model confidence scores to prioritize human review for items in complex domains.
The better approach uses dynamic thresholds. Simple factual items with high confidence scores might need 10% review. Complex scenario-based items with lower confidence trigger 100% review. The system adapts based on observed patterns, not arbitrary percentages.
Explainability logs that protect against future challenges
Documentation becomes your defense when someone challenges an AI-influenced assessment decision six months later. Most organizations either over-document (creating unusable audit trails) or under-document (leaving critical gaps).
Explainability logs need to capture the why behind AI decisions without drowning in technical detail. For each AI-assisted assessment element, track:
Decision points:
-
What specific AI tool or model was used
-
What prompt or input generated the output
-
What human reviewed or modified the output
-
What validation checks were performed
Context markers:
-
Assessment purpose and stakes level
-
Candidate population characteristics
-
Any special accommodations or modifications
-
Relevant performance benchmarks
Quality indicators:
-
Confidence scores or uncertainty measures
-
Similarity to validated content
-
Any flags or warnings generated
-
Human reviewer agreements or disagreements
The logging system should be searchable and structured—not just walls of text. When a candidate appeals their result or an auditor requests documentation, you need to quickly reconstruct how AI influenced that specific assessment without hunting through spreadsheets.
Red-team testing for bias detection
Red-team testing for assessment AI isn't about achieving perfect algorithmic fairness. It's about discovering the specific ways your tools fail before they affect real candidates. Structured adversarial testing works far better than hoping issues surface naturally.
Start with demographic swap testing. Take AI-generated assessment content and systematically swap demographic markers: change "Jennifer" to "Jamal," "soccer" to "basketball," "suburban" to "urban." If scores or difficulty ratings shift, you've found something worth addressing.
Surface-level testing isn't enough, though. You need domain-specific bias probes. An AI generating technical interview questions might consistently make problems harder when prompted about "senior developer" versus "developer" roles, inadvertently creating age-related barriers. Questions about "leadership" might skew toward military or sports metaphors that favor certain backgrounds.
Red-team testing should also simulate how candidates might game the system. If people discover that your AI essay scorer rewards certain vocabulary or sentence structures, they'll exploit that. Your testing needs to identify those vulnerabilities before they become widely known.
A financial services firm learned this when their AI-powered assessment platform started giving higher scores to responses that included industry jargon—regardless of actual comprehension. Candidates started memorizing terminology lists instead of developing real skills. By the time they caught it, hundreds of assessments were compromised.
Connecting bias detection to validity evidence
Bias testing can't exist in isolation from your broader validity and reliability framework. Every bias detection finding needs to connect back to whether your assessments actually measure what they're supposed to measure.
The connection usually surfaces through differential item functioning (DIF) analysis. When AI-generated items show different difficulty patterns across demographic groups, that's not automatically bias—it might reflect genuine skill differences. You need evidence to distinguish between the two.
Bias indicators:
-
Unexplained score differences across groups
-
Content that favors specific cultural knowledge
-
Language complexity beyond what the skill requires
-
Scenario assumptions about life experience
Validity supporters:
-
Score differences that align with job performance data
-
Content directly tied to role requirements
-
Language complexity appropriate to the role
-
Scenarios based on actual work situations
The operational challenge is maintaining this analysis as your AI tools evolve. A model update might introduce new biases or eliminate old ones. Governance needs continuous monitoring, not just initial validation.
Periodic audit scripts and monitoring routines
Manual bias checking doesn't scale once AI becomes embedded in your assessment operations. You need automated monitoring that runs continuously, flagging issues before they affect outcomes.
Audit scripts should check both technical and operational metrics:
Technical monitoring:
-
Model drift detection (are outputs changing over time?)
-
Confidence score distributions (is the AI becoming less certain?)
-
Error rate trends (are mistakes increasing?)
-
Processing time variations (are there performance issues?)
Operational monitoring:
-
Review override rates (how often do humans reject AI outputs?)
-
Candidate challenge patterns (are certain groups complaining more?)
-
Score distribution shifts (are results becoming skewed?)
-
Usage pattern changes (are people working around the system?)
Build these checks into regular assessment operations, not separate compliance exercises. When someone generates new test items, bias checks run automatically. When scores get calculated, differential impact analysis happens in parallel. Monitoring becomes part of the workflow.
A university testing center automated this after spending months doing manual reviews. Their scripts now check every AI-generated question against a bias keyword list, analyze reading complexity, and compare difficulty estimates across demographic models. What used to take days happens in minutes, with exceptions flagged automatically for human review.
The coordination challenge across stakeholders
AI governance for assessments fails most often at organizational boundaries. IT implements AI tools without understanding assessment validity. The assessment team sets requirements without grasping technical constraints. Legal reviews policies without considering operational workflows. Each group optimizes their piece while the overall system fragments.
Organizations that handle this well create cross-functional governance teams that meet regularly—not just during implementations. These teams need representation from:
-
Assessment and psychometric specialists who understand validity requirements
-
IT and technical staff who manage AI systems
-
Legal and compliance officers who interpret regulations
-
Operations managers who oversee daily workflows
-
End users who actually interact with the tools
Representation alone isn't enough. You need clear decision rights. Who can approve new AI tools? Who determines review thresholds? Who investigates bias complaints? Without defined roles, every issue becomes a committee discussion that delays response.
The governance team also needs escalation protocols. When an audit script flags potential bias, who gets notified? How quickly must they respond? What triggers an assessment pause versus continued monitoring? These aren't theoretical questions—they're operational realities that need predetermined answers.
Technology infrastructure that enables governance
Governance policies mean nothing without systems to enforce them. Most organizations try retrofitting existing assessment platforms with AI governance features, creating tangled systems that nobody fully understands.
-
Audit trail systems that automatically capture every AI interaction, not just final outputs. When someone generates 50 questions but only uses 5, you need records of all 50 plus the selection criteria.
-
Version control that tracks both AI model updates and assessment content changes. When bias appears, you need to trace whether it came from new training data, model modifications, or prompt engineering changes.
-
Integration APIs that connect AI tools, assessment platforms, and monitoring systems. Manual data transfer between systems creates gaps where governance breaks down.
-
Alerting mechanisms that notify the right people at the right time. Not every anomaly needs immediate attention, but critical issues can't wait for monthly reviews.
AI-powered operational software built for assessment management can centralize these capabilities rather than cobbling together multiple tools. The platform maintains governance controls as a core feature, not an afterthought. Automated monitoring handles routine checks while surfacing exceptions for human review—so instead of manually combing through logs, teams get alerts when patterns suggest potential issues.
This approach transforms governance from a compliance burden into a workflow enhancement. The same systems that flag potential bias also identify high-performing items. Audit trails that protect against challenges also provide insights for improvement. The monitoring that ensures fairness also helps optimize efficiency.
Preparing for regulatory scrutiny
The regulatory landscape for AI in assessments keeps evolving, and the scrutiny is only increasing. Organizations that establish strong governance now avoid scrambling when new requirements emerge.
Current regulations focus primarily on:
-
Transparency in automated decision-making
-
Ability to explain adverse impacts
-
Evidence of bias testing and mitigation
-
Documentation of human oversight
-
Candidate rights to appeal AI decisions
Enforcement varies dramatically by context, though. Educational assessments face different requirements than employment testing. Healthcare certifications have unique constraints. International operations multiply the complexity.
Organizations handling this well build flexibility into their governance frameworks. They exceed minimum requirements in critical areas while maintaining operational efficiency. They document everything but organize it for quick retrieval. They test continuously but focus resources on high-risk areas.
One global consulting firm maintains separate governance protocols for different assessment types but uses shared infrastructure for monitoring and documentation. Their AI tools automatically adjust behavior based on jurisdictional requirements—when European privacy laws differ from US regulations, the system adapts without manual intervention.
The path forward
AI governance for assessments isn't about restricting innovation or adding bureaucracy. It's about creating operational frameworks that let you actually use AI's benefits without compromising assessment validity and fairness.
The organizations getting this right share a few common patterns. They established clear policies before scaling AI adoption. They built monitoring into workflows rather than treating it as separate compliance work. They invested in infrastructure that makes governance automatic rather than manual. And they recognized early that AI governance is an operational challenge requiring coordination across technical, assessment, and business teams—not just a technical checkbox.
The biggest mistake is waiting for perfect governance before using AI at all. Start with low-risk applications, establish basic controls, then expand gradually. Build governance capabilities alongside AI adoption, and adjust based on what you actually learn.
The goal isn't preventing every possible issue. It's creating systems that detect and address problems quickly. When teams trust that proper controls exist, they're more willing to explore what AI can actually do for their assessments.
The question isn't whether to use AI in assessments—it's how to use it responsibly. Strong governance makes that possible, turning AI from a liability into a genuine advantage for delivering better, fairer, and more efficient assessments.
Ready to revolutionize your evaluation process?
Join over 2,000 organizations using Evaloly to optimize assessments, improve learner outcomes, and make data-driven decisions.

